

The API Architecture you should choose depends on the workflows you want to enable for your consumers. This is one of those places where you can make lots of bad decisions, and no one will ever universally think you made the right ones. If your API is used by more than one group (i.e., internal teams, customers, 3rd parties), your chances of applause go to nearly zero.
There are three main types of APIs available today; REST, GraphQL, and RPC. It's likely that several people on your team love or hate each one for totally unrelated reasons. REST is easy to create and use (initially), GraphQL simplifies clients (with a learning curve and potentially complex backend), and RPC optimizes consumer use cases (assuming you know them). Generally, backend engineers want to use REST, Frontend loves GraphQL, and people who think they know everything already use RPC. This is because each one's preference pushes work onto the other's plate. Go Team!
The three options differ in how they balance simplicity, flexibility, and precision. These three attributes can move from the client to the service side, depending on each. Understanding who your consumers are and their needs will help you decide on which paradigm best suits them.
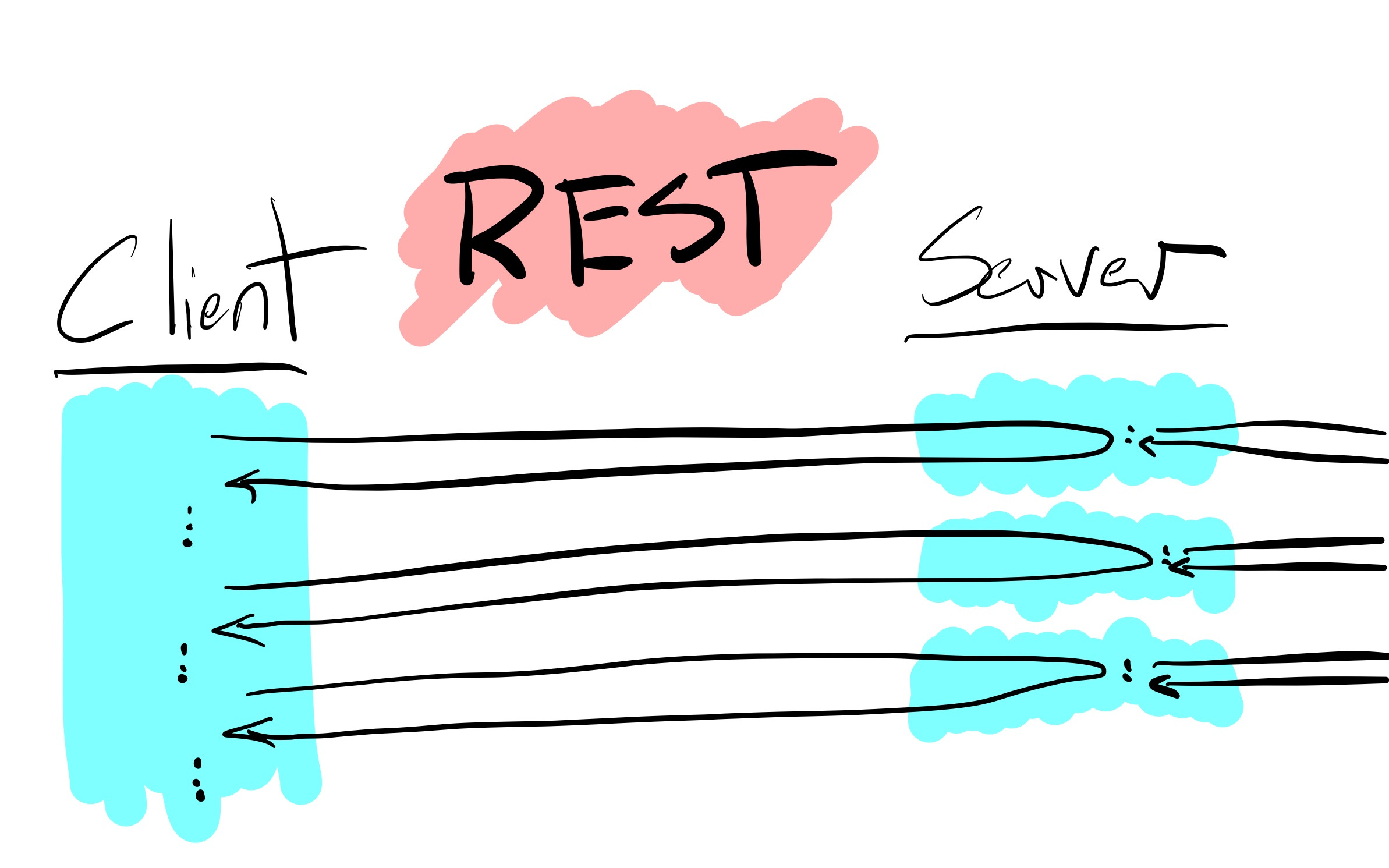
REST is well known and standardized enough across the industry that it is usually the defacto choice for most companies, regardless of how effective it is for consumers. It provides a simple set of actions (usually CRUD) over individually addressable resources. The simplicity of API actions moves implementation complexity to clients. I'm not going to go into the design of REST here and why its decisions are good or bad. You are intelligent people and likely have made a few of these already.
"No one got fired for making a REST API."
Your consumers can build any application they want using your REST API. As long as anything they want to create doesn't have to be fast and your data model is simple. I have yet to see these requirements survive real-world customers. In practice, data is messy, and people complain when things are slow. To you. They're going to complain to you.
The constraints of REST's CRUD actions are difficult to map to even mildly complex problems pragmatically. Every REST API I've ever made or used ended up with "Service Endpoints" (also called Controllers) that did special operations outside of CRUD. These can be transactions that involve multiple resources or specialized RPC endpoints because the client code just got that complex, and they made you add one.
The work of combining the many simple endpoints into something the consumer wants falls on the consumer’s side. This means business logic complexity is on the client, and servers will potentially have to handle many API calls. Ideally, these API calls are tiny and fast. In reality, someone will use every expensive filter available on a call and call you in a fork loop. Rate limits be damned!
The best part of REST? Your consumer already understands it. There is a near-zero learning curve. You can hire developers with experience in building them. It works with all languages and technology stacks; server and client. Consumers may even have tooling around OpenAPI already. After a few service endpoints, people can make anything they want using it. Plus, No C-Level is going to ask for justification for using it. The barrier to entry is fantastic all around. If you don't yet know what your consumers want to build using your API, REST is a great option.
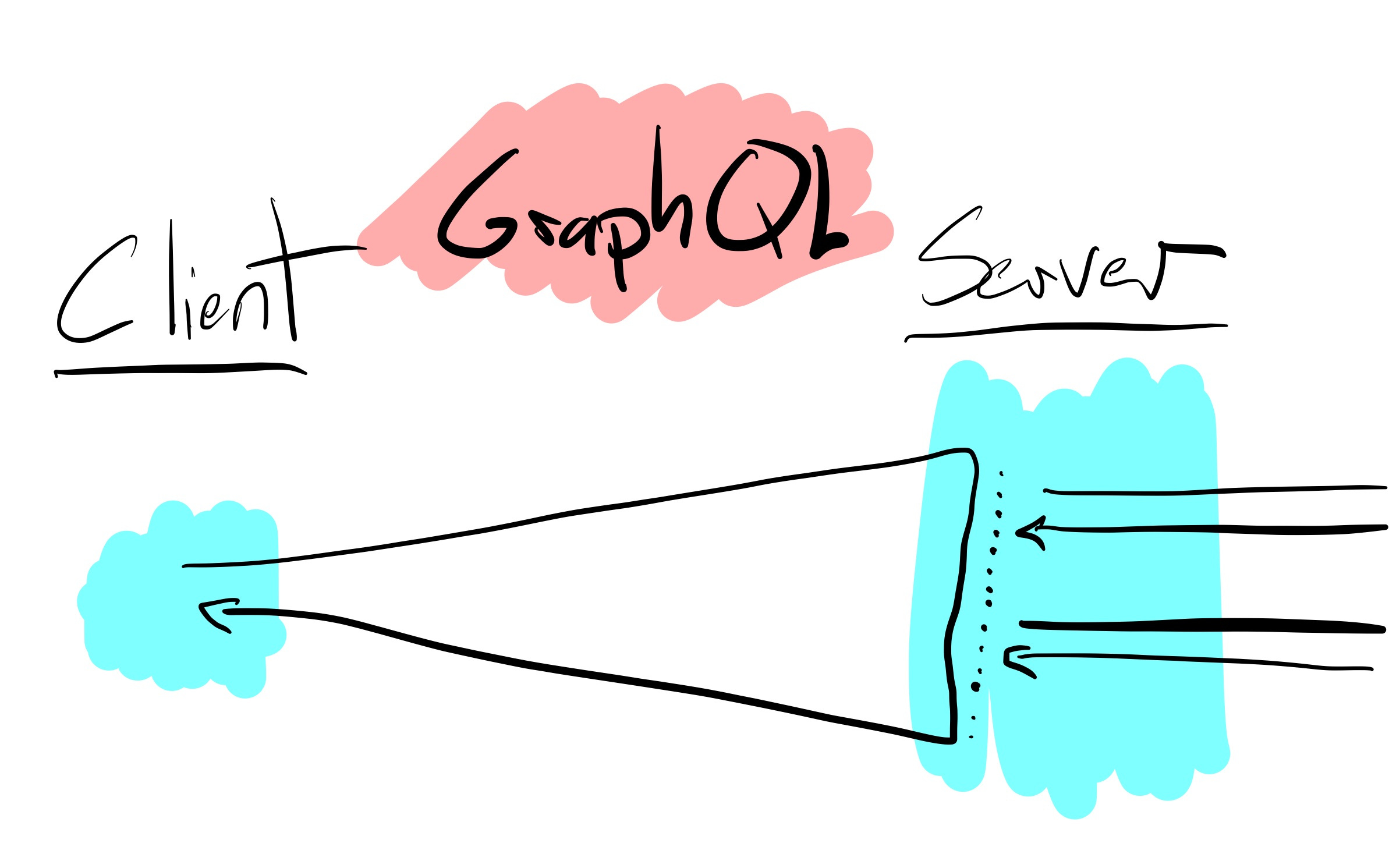
GraphQL is a response to the client complexity caused by REST APIs. And that response was “web programming is enough of a disaster. This is your problem now.” to backend developers. GraphQL inverts the pattern in REST and allows clients to request data over many resources, potentially filtered and aggregated, in any arbitrary query. If this sounds like SQL, congratulations, you get the name now. Some critical aspects of databases are missing.
There is no query planner, which means no optimizations automatically. Nearly any optimization needs to be hand implemented or even monkey patched into the otherwise linear execution model. Initial GraphQL implementations tend to be N+1 database loops when the REST version was a single call. Combined with arbitrary queries, this means it’s easy to ask the server to do something impossible. But you can’t know until you try.
“Hope is not a strategy.”
When I talk with teams about this, the answer is usually some form of “engineering rigor” is required to be good citizens. If you say that works for you, I don’t believe you. As if from a time machine from the era of throwing SQL over to DBAs, I have heard frontend developers say, “This is the data required. It’s your job [everyone else] to make it fast”.
There is new complexity for clients when you compress many network calls into a single query. That query that works fine today can break tomorrow, and it isn’t easy to know why. Anything from a seemingly minor update to a service in the call chain to the data shape-changing requiring new hand optimizations on the backend is possible. There is one particularly challenging place, though; rate-limiting.
Rate limiting for GraphQL will always require a custom solution. There is no general system you can apply that gives you adequate protection and is understandable to clients. Your bespoke implementation will still not be coherent to the client.
There is no way to know if your query will exceed any rate limit without executing it. Let’s use Github, whose GraphQL API is pretty legit, and how they do rate-limiting as an example. You get 5,000 points an hour. To know how many points a query costs, execute it (against your 5,000 points). You can ballpark this yourself, but it’s not perfect.
Rate limits are difficult because the complexity that moved to the server can easily DDOS you now with almost no latency. Those arbitrary queries can be 1,000’s of expensive requests to fulfill internally. Rate limiting internal services the way we do REST APIs can impact multiple customers if done wrong, and when done right can cause otherwise valid queries to time out on clients. Github picked “nodes” and “points,” you need to pick something related to how your data is structured, and you need to aggregate it.
“Most discussions of GraphQL focus on data fetching, but any complete data platform needs a way to modify server-side data as well.”
-The first sentence in GraphQL’s documentation on mutations.
The primary use case for GraphQL is reading data. Updates are tacked on. I’ve seen teams use GraphQL for reads and existing REST APIs for any modifications. This context switching is difficult, and since the “API” is now distributed over two places, they eventually diverge, and consumers need to munge data between the two to get things to work. This can even happen if you do mutations within GraphQL, as they call for having specific “Input Types” that need to be created and managed independent of data types. GraphQL’s value is in reads and the aggregation over many types. Write heavy APIs aren’t likely to get many wins using it.
Since GraphQL is still a young technology with most of its value seen in web frontends, many third parties and customer integration teams aren’t asking for it. When the consumers are coworkers, and you can Slack the person who just added a query killing things, it’s much easier to plan for new use cases and find solutions to problems. The experience in web development is a giant leap forward with GraphQL. Honestly, they need it, too; it has been a tough ten years for them. Since fewer requests are required, there are performance implications that improve as you expand globally, and clients are further from where ever your backend is hosted. The Subscription functionality opens the door for some fun possibilities that are difficult with the other two API architectures.
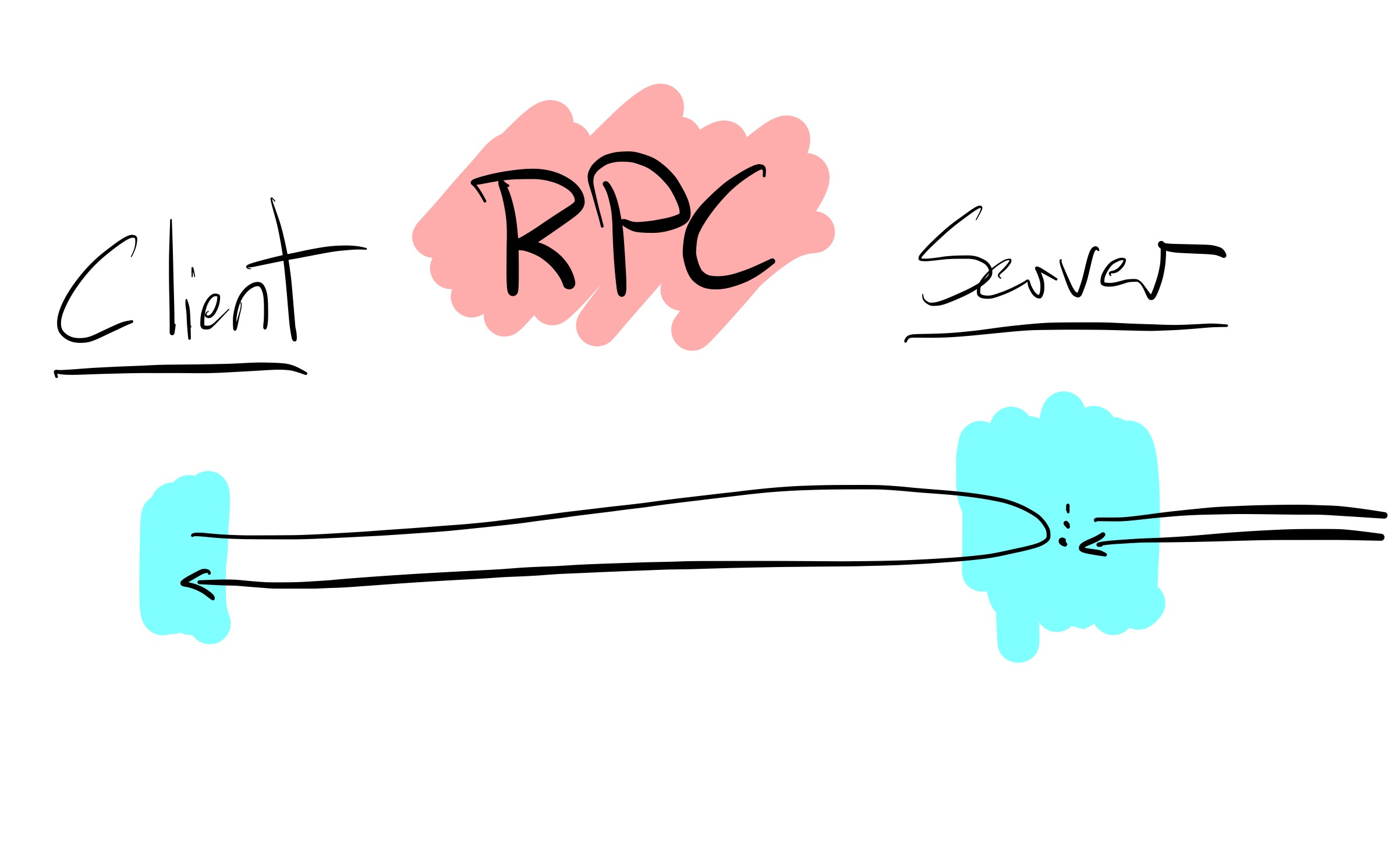
It's easy to build something unusable with RPC. If REST is simple and GraphQL is flexible, then RPC is precise.
When build REST APIs, you make CRUD endpoints and tell consumers to figure it out. With GraphQL, you let consumers ask for anything, and you have to figure it out. Unlike the other two, to make an RPC API, you first need to understand what your consumers want to build using the API.
One of the significant drawbacks of RPC is there are no standards on what it means. This gap in meaning requires you to make a lot of decisions. Important decisions that don't have a ton to do with the API's problem are trying to solve. What decisions are these? Do you use JSON over HTTP? Isn't SOAP an RPC system technically? Ok, gRPC handles most of this. Let's use that. How do we manage Protobuf files and client generation? Will, our customers use our clients, so should they generate their own? In what languages?
This barrier to entry exists for you and your consumers. To justify the effort of hurdling it, your API needs to supply the correct functionality in an ergonomic way that other methods wouldn't allow. These use cases exist, and it may be that only an RPC-style API gives everyone the abilities required to solve it. Statistically, though, yours isn't one.
Creating an RPC API requires the most substantial knowledge of what your consumers need to build using the API of all methods. Keeping consistent with the initial load of technical decisions necessary, you also have to frontload the design and customer research to figure out what endpoints to include in the actual API and what form. When there is misalignment here, you can end up with APIs that don't provide key functionality required by consumers and no flexibility for them to code around it.
A well-crafted RPC API can almost always outperform any other version. ("Can" being the operative word over "will") When aligned with the consumer's intent, specialized endpoints simplify the implementation of each side of the API. Consumers can make minimal, precise calls. The server can optimize each endpoint and its execution individually without worrying about unknown options and combinations of queries. Together, this can outweigh the initial one-time design and onboarding costs.
Many of the best use cases for RPC are to support more bespoke consumer use cases. Things like streaming data, offline support, and domains where multiple resources are commonly modified transactionally.
“Its better to be consistent than correct”
There are other considerations when making an API. If you already provide APIs that will interact with this one, don’t mix styles. Any consumer will prefer a consistent, non-ideal experience to a half ideal, half non-ideal one they need to juggle and hack together constantly.
There is no general Best Practice on what paradigm to use (anyone who says differently is selling you something). These different architectures exist to solve different use cases. You need to understand your consumers, business context, and internal constraints to make the choice that is right for you. If this sounds hard, welcome to higher-level design. It is hard.
TL;DR (Ha! You already read it)
Consider what use case you want to enable for consumers. The problem you want to solve is the most important thing to understand. Here are some things to consider:
Are the consumer use cases general open-ended ones, or does this API do a specific task? Very narrowly targeted APIs can benefit from RPC on both the client and server. More general ones require more flexibility afforded by REST and GraphQL.
Are you willing to take on some complexity to make the API easier to use? In REST, this can be additional Service Endpoints. Or go in for GraphQL/RPC.
Know your consumers. Internal teams are easy to teach new things and get feedback from. Unknown external consumers may not have engineering departments and need to work with Low/No Code systems. Some measure Time to 200.
Minimize the API. Whatever paradigm you use, don’t expose information that isn’t needed and complicate your future plans. This is called the Iceberg Pattern.
Once you put an API out there, it isn’t easy to take it back. Start small.